Tianwei Ni 倪天炜
I am a final-year PhD student at Mila - Quebec AI Institute and Université de Montréal,
advised by Pierre-Luc Bacon. In the previous years, I worked closely with
Benjamin Eysenbach at Princeton University and Aditya Mahajan at McGill University.
I also worked at Amazon as an applied scientist intern.
My research centers on deep reinforcement learning (RL).
A central theme in my work is treating history as a first-class citizen to address partial observability and modeling its representation (agent state) through self-supervised learning and sequence modeling.
I explore various training paradigms in deep RL:
(1) Canonical RL that learns from scratch,
(2) Offline RL pretraining that learns from passive datasets,
(3) RL post-training that fine-tunes pretrained models for complex tasks such as reasoning with large language models.
News
- May 2025: One paper got accepted at RLC. See you in UAlberta, Edmonton.
- Nov 2024: I am honored to receive the RBC Borealis AI fellowship (10 PhD students in Canada every year).
- Sept 2024 - Feb 2025: I started my applied scientist internship at Amazon Web Services in Santa Clara, supervised by Rasool Fakoor and Allen Nie in the generalist agent team.
- Jan 2024: One paper got accepted at ICLR as a poster. See you in Vienna!
- Sept 2023: One paper got accepted at NeurIPS as an oral. See you in New Orleans!
- Aug 2023: I passed my predoc exam and became a PhD candidate.
|
|
Recent Work
Please see the full publication list in Google Scholar.
Notation: * indicates equal contribution.
|
Teaching Large Language Models to Reason through Learning and Forgetting
Tianwei Ni, Allen Nie, Sapana Chaudhary, Yao Liu, Huzefa Rangwala, Rasool Fakoor
arXiv /
Inference-time search improves reasoning in LLMs but is expensive at deployment.
We propose unlikelihood fine-tuning (UFT), which trains LLMs to follow correct reasoning paths and forget wrong ones from various reasoning algorithms,
while enabling fast inference.
Understanding Behavioral Metric Learning: A Large-Scale Study on Distracting Reinforcement Learning Environments
Ziyan Luo, Tianwei Ni, Pierre-Luc Bacon, Doina Precup, Xujie Si
Reinforcement Learning Conference (RLC), 2025
arXiv /
Distracting observations in the real world can be addressed by metric learning in RL.
Our extensive study highlights the often-overlooked roles of layer normalization and self-prediction in improving these methods.
Do Transformer World Models Give Better Policy Gradients?
Michel Ma*, Tianwei Ni, Clement Gehring, Pierluca D'Oro*, Pierre-Luc Bacon
International Conference on Machine Learning (ICML), 2024
and ICLR 2024 Workshop on Generative Models for Decision Making (oral)
arXiv
How to design world models for long-horizon planning w/o policy gradient explosion?
Use f(s[0], a[0:t]) w/ Transformer, instead of recursively calling f(s[t], a[t]).
Bridging State and History Representations: Understanding Self-Predictive RL
Tianwei Ni, Benjamin Eysenbach, Erfan Seyedsalehi, Michel Ma, Clement Gehring, Aditya Mahajan, Pierre-Luc Bacon
International Conference on Learning Representations (ICLR), 2024
and NeurIPS 2023 Workshop on Self-Supervised Learning: Theory and Practice (oral)
arXiv / OpenReview / 1-hour Talk /
Provide a unified view on state and history representations in MDPs and POMDPs, and further investigate
the challenge, solution, and benefit of learning self-predictive representations in standard MDPs, distracting MDPs, and sparse-reward POMDPs.
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
Tianwei Ni, Michel Ma, Benjamin Eysenbach, Pierre-Luc Bacon
Conference on Neural Information Processing Systems (NeurIPS), 2023 (oral)
and NeurIPS 2023 Workshop on Foundation Models for Decision Making
arXiv / OpenReview / Poster /
11-min Talk / Mila Blog /
Investigate the architectural aspect of history representations in RL on temporal dependencies -- memory and credit assignment, with rigorous quantification.
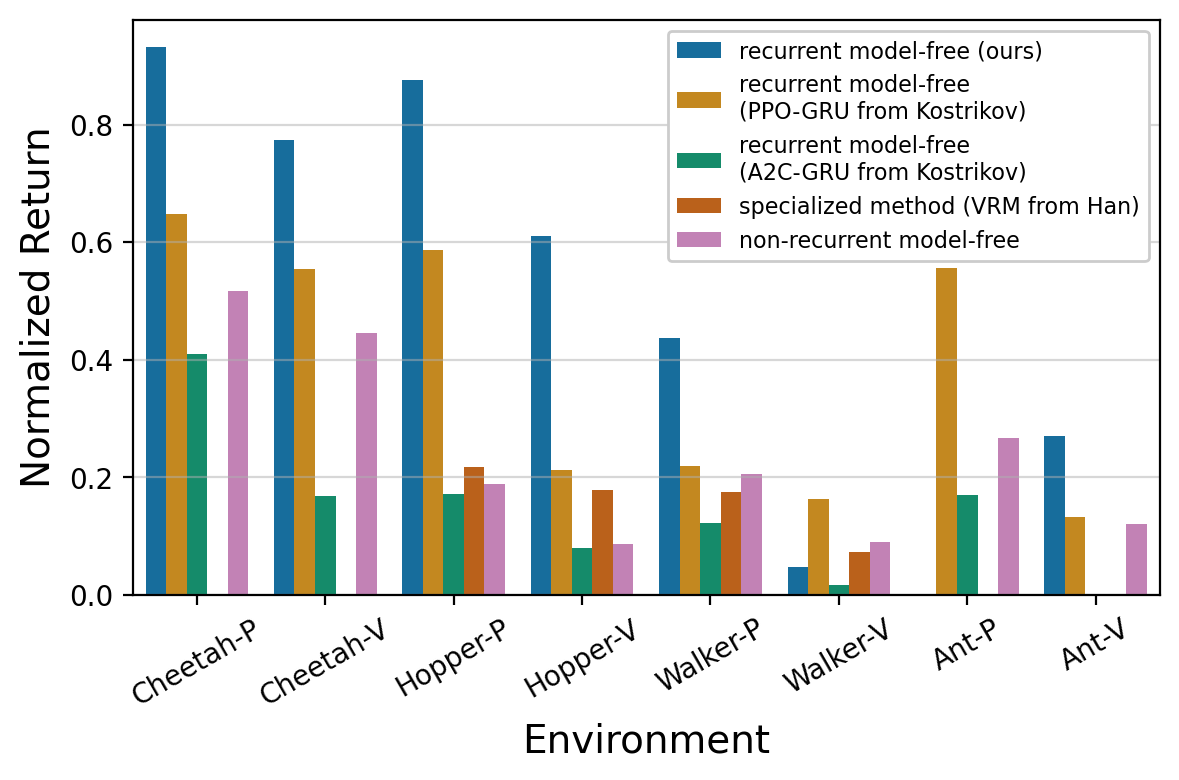
Recurrent Model-Free RL Can Be a Strong Baseline for Many POMDPs
Tianwei Ni, Benjamin Eysenbach, Ruslan Salakhutdinov
International Conference on Machine Learning (ICML), 2022
project page / arXiv
/ CMU ML Blog /
Find and implement simple but often strong baselines for POMDPs,
including meta-RL, robust RL, generalization in RL, and temporal credit assignment.
Before embarking on my PhD journey, I was a research intern on embodied AI mentored by Jordi Salvador and Luca Weihs at Allen Institute for AI (AI2).
I earned my Master's degree in Machine Learning at Carnegie Mellon University, where I
studied deep RL guided by Ben Eysenbach and Russ Salakhutdinov, and explored human-agent collaboration advised by Katia Sycara.
My research journey started with computer vision for medical images supervised by Alan Yuille at Johns Hopkins University.
I earned my Bachelor's degree in Computer Science at Peking University.
Fun fact: I have experienced university education in three languages - Chinese, English, and French.
|
Website template is credit to Jon Barron's source code.
|
|




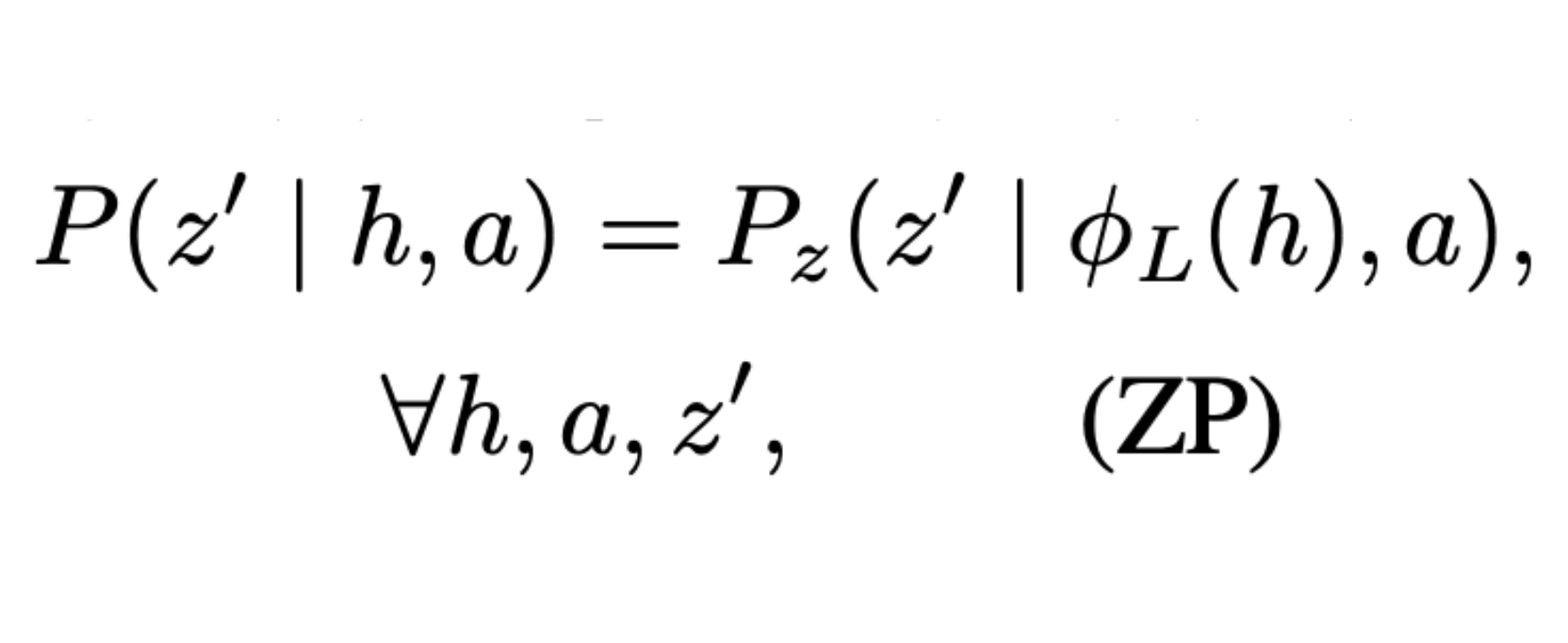

{kind=link}